
System downtime can hit any online business at any time. And the way you find out about disruptions – a barrage of tweets, emails or chats – isn’t a nice experience.
You’re never ready and there’s never an ideal moment to handle system downtime apart from ASAP. It’s Murphy’s Law of ‘whatever can go wrong, will go wrong’. For many businesses that happened on the 28th February 2017 when AWS had a system outage.
But as bad as things may seem during the crisis, it’s what you do after your system outage that has the biggest impact. Communication and transparency are the cornerstones of regaining customer trust and satisfaction.
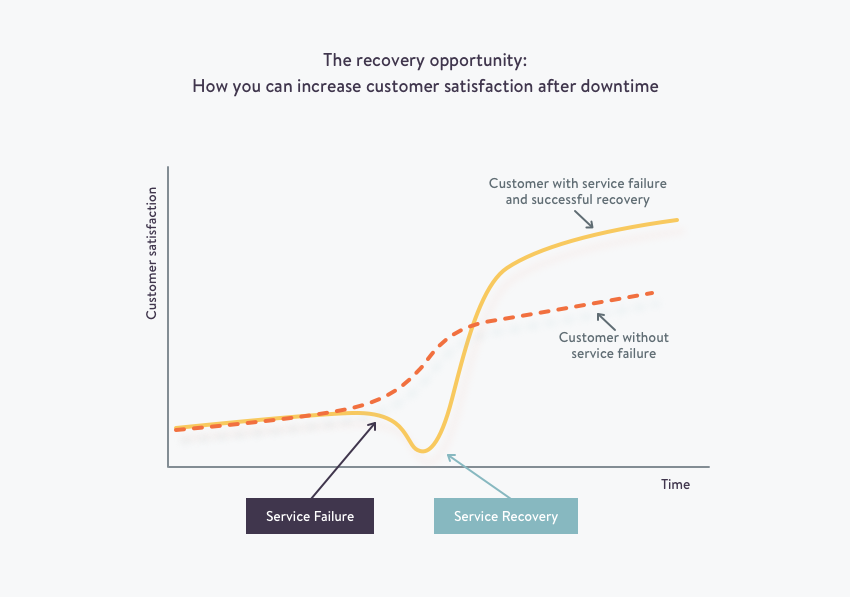
Customer satisfaction depends on your recovery from system downtime
The way you handle a service interruption can make or break your business. Handling a negative situation well and restoring customer faith in your business can improve overall satisfaction with your product or service. This is known as the service recovery paradox.
Today, we’re not here to tell you how to communicate with customers during a crisis. (You can see how in this excellent breakdown of how Slack handled their downtime in 2015).
We’re here to tell you how to keep the faith in your service once you’ve experienced downtime, and what you can do to restore customer faith.
Identify intermittent system outages
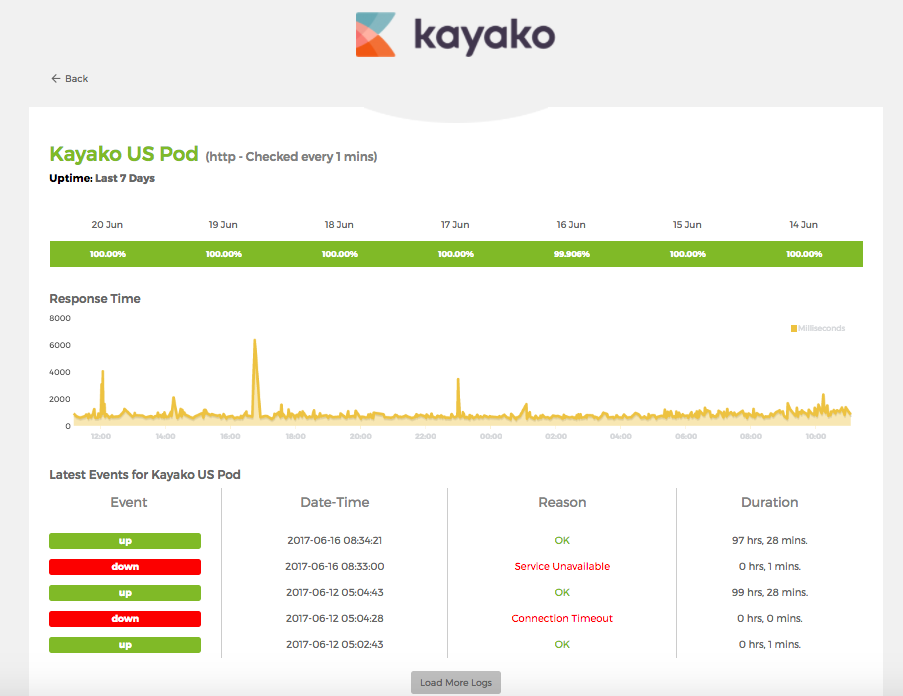
In May, Kayako customers came to us reporting service disruption after experiencing brief downtime lasting 3-8 minutes each. These occurred approximately once a day during the week and we recorded 16 instances of disruption.
But isolating the issue was difficult. In the first week, we worked 24/7 to find and put our finger on the trends causing our system outage.
We isolated customers, databases, and query types. At first, it appeared to be random. Nothing was consistent and we couldn’t put our finger on anything apart from that it was happening in the US.
Keep your customers in the loop
This was not an ideal situation to leave our customers in. They had no idea what had caused the outage, and had far less information than we had. In the worst cases, their customers were demanding answers that they couldn’t provide.
Our support team were given a full brief of the issues and the steps we were taking to fix the problem. We provided some real-time resources to help our support team be as transparent as possible with our customers:
- A status page (we recommend using: StatusPage or Sorry™.)
- A live independent third party monitoring service, Uptime Robot. This recorded every instance of interruption.

The search behind the scenes
The disruptions we were getting were 1-2 times a day, but short in duration before our fail-over systems kicked in. And it was lucky we had those, as it meant a disruption of a few minutes rather than a 20 minutes wait for the server to reboot.
Although the intervals of down time were short, the frequency of the issues frustrated customers.
But we had another week of problems persisting before we narrowed it down to a trend. It meant we were risking our service promise of 99% uptime.
Finding and handling the issue: don’t pass the buck
When we finally found the issue, we realized it was outside of Kayako.
These disruptions were caused by the freezing up and crashing of our primary database platform (a platform product called Amazon Aurora). Customers would see an “Internal server error” page for those few minutes, until we failed-over to our backup Amazon Aurora instance (which took up to 10 minutes).
Once we combed through everything we possibly could to isolate the issue, it was escalated with Amazon, presuming there may be something we were missing. After some digging, Amazon engineers realised we were facing two bugs in their Aurora product which manifest themselves in rare circumstances:
- The first and most serious bug (which caused the Amazon Aurora crashes) occurred when the database refreshed its privileges table. This put the database server into a deadlock from which it would never recover until restarted:

- The second bug slowed down our recovery from the first bug. We should be able to failover to our redundant Amazon Aurora setup within a couple of minutes. Instead, it took up to 10 minutes each time, because the second bug prevented an automatic and instant failover (so we had to manually intervene).
We were adamant about not passing the buck. Although the service wasn’t owned by us – and there was no fix we could provide – we didn’t want our customers to feel that it suddenly made it okay for us.
Amazon were excellent with us in helping find a work around to stop triggering the bug.

You have a job to do by your customers. Passing the buck is lazy, especially when customers are relying on your service to support their business.
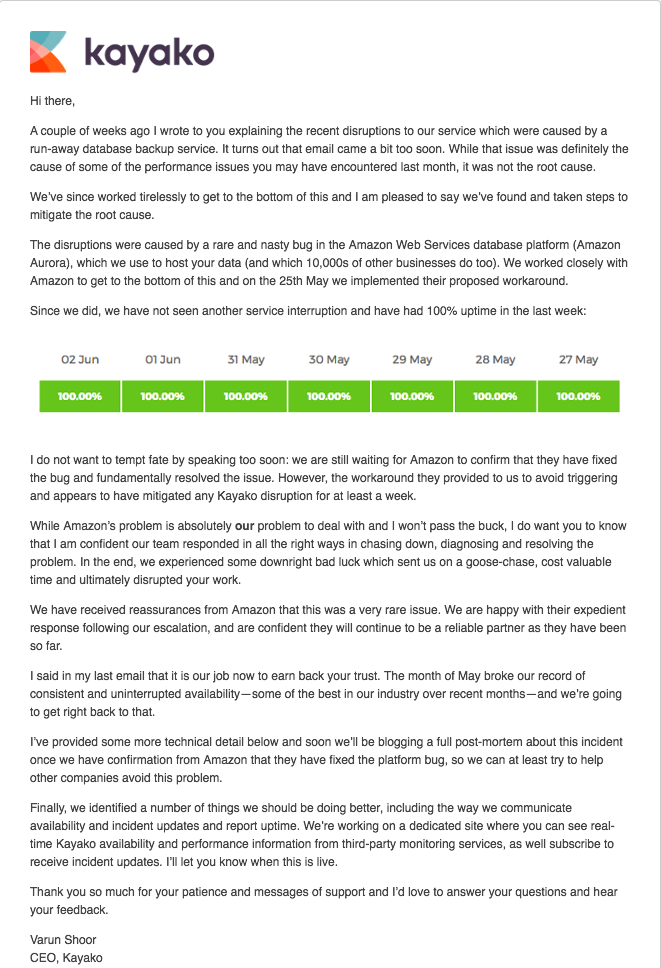
Send a personal email from the top to apologize for service outages
After identifying the issue and keeping frequent, transparent communication with customers, you have to be mindful of describing how the issue was handled.
As CEO, Varun felt responsible for communicating with customers and sent an apology email from his personal email address.
A lot matters in customer communication over sensitive issues such as downtime. It’s vital you don’t dump the blame on others or use technical language.
This why the whole team was involved in the production of the email. It may seem overkill to involve your engineers, support, and marketing teams to craft an email, but the communication of issues is vital for regaining customer trust.
We wanted to be clear to customers that these things can happen, and if they happen again, we have the right skills and experience to resolve it quickly.
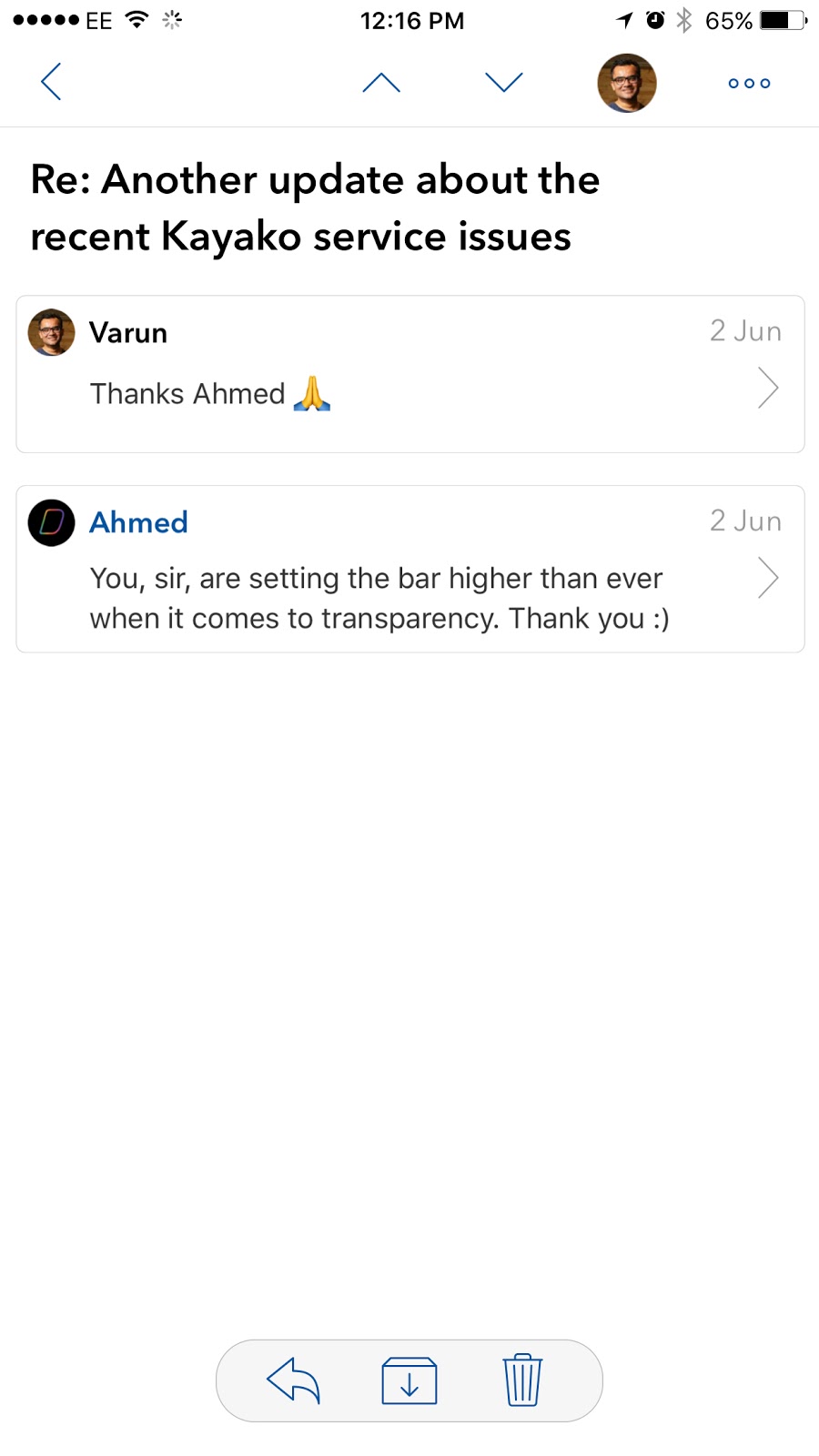
And they thanked us for it.
Apologize for downtime and rebuild satisfaction
As downtime or system outages can hit your business at any time, you need to be prepared to act with ownership over the issues. Use the principles of service recovery and combine that with transparency and a continuous loop of communication to regain customer trust and satisfaction with your business.
Having your CEO claim ownership of the problem helps customers know that the issue is being taken seriously and isn’t just handed off to the engineering and support teams to handle. Sometimes it’s best when personal apologies come from the top.
[hs_action id=”9024″]